Best practices for error catching and handling

Front end developer specialising in JavaScript and React. Experienced in all aspects of modern front end development. Passionate about making accessible, secure and performant software. Experienced trainer and lead.
Catching and handling errors is an important part of error handling.
Here are some best practices for it. Generally, it's good to:
- be very thorough with your error checking
- do your error checking first
- handle errors at the earliest appropriate place
- (for exceptions) put the minimum code you can in your try blocks
- restore state and resources so the program can keep executing correctly
Here are the best practices in more detail.
(Note: For this article, "error" is defined in Terminology - Errors and non-errors. It means anything you might throw an exception or return an error value for. It doesn't just mean an "unrecoverable error".)
Be very thorough with your error checking
Unfortunately, programmers aren't perfect. We create bugs and make mistakes. In fact, we do that quite often. That's why we have so many error correction tools to help us.
So, in general, you should go by the assumption that everything in your program that can fail will fail. Other things that you didn't think of will also fail.
To minimise the issue, you should be very thorough with your error checking. Always catch all possible exceptions and check all error values. Then, handle them appropriately.
Check for errors first
This one is a stylistic convention.
In your code, it's good to do your error checking before anything else. Leave the normal program execution for after.
For example, in methods that throw exceptions, try to check for errors and throw the exception as early as possible.
Here's a code example:
class Example
{
public void Foo(string a)
{
if (a.Length === 0)
{
throw new InvalidArgumentException("Parameter {a} must not be the empty string.");
}
// normal program execution
}
}
Method Foo starts by doing its error checking. The normal code execution comes afterwards.
Avoid doing something like this:
class Example
{
public void Foo(string a)
{
// do some "normal program execution" that doesn't need parameter `a`
// check parameter `a` right before you need it
if (a.Length === 0)
{
throw new InvalidArgumentException("Parameter {a} must not be the empty string.");
}
// more normal program execution
}
}
In this code, Foo executes some code. Then, it does some error checking for parameter a.
The same principle applies to checking error values. Try to check for errors before you continue your normal program execution.
Here is a code example:
function foo() {
const result = bar();
if (result.error) {
// handle error
}
else {
// normal code execution
}
}
The code above first checks for errors. Then, it continues normal program execution.
This organises your code into recognisable blocks. Errors first, normal code after. It makes your code easier to scan through and easier to understand.
It also helps with debugging. When an error is thrown, less normal code will have ran. This reduces the amount of code you'll have to check through when debugging.

Handle errors at the first appropriate place
Sometimes, you can't handle errors immediately. You might need to propagate them to higher level code.
To showcase this, consider this example: You have a function that searches the file system for a file. If it finds it, it reads its contents. Otherwise, it throws an exception. How should the code handle this exception? Should it:
- crash the program?
- create a new file?
- search for a backup file in a different location?
- notify the user that the file couldn't be found and ask them to try a different file?
The file system code doesn't know. Different programs will want different behaviour if the file isn't found. This means that the file system code can't have hardcoded behaviour to handle the exception.
Instead, the exception should be handled at a more appropriate place. The place that can decide what to do about it. Often, that means some code higher up in the call stack. So, the exception (or error value) needs to propagate up to that place.
For exceptions, that means that you should let the exception bubble up. Then, have a try / catch block at the place where you'll handle it.
For error values, you'll have to manually return them until they reach the correct place in the call stack.
Having said that, you should handle errors at the first appropriate place. Don't propagate them higher than necessary. The earlier you handle errors, the closer they'll be to the code that raised them. This makes the execution flow of the code easier to track and understand.
Here's a code example where we search the database for a record:
// server.js
import { getSpriteById } from './myDatabase.js';
app.get('/:spriteId', async (req, res) => {
const spriteId = req.spriteId;
try {
await getSpriteById(spriteId);
} catch (error) {
// exception from database is handled here.
// In this case, it responds with a 404.
res.sendStatus(404);
return;
}
res.send('Sprite found');
});
app.post('/foo', async (req, res) => {
const spriteId = req.body.spriteId;
try {
await getSpriteById(spriteId);
} catch (error) {
// exception from database is handled here.
// In this case, it redirects
// to another page for the user to fill in correct information
res.redirect('/form');
return;
}
res.send('Data accepted');
});
// myDatabase.js
const db = await connectToDatabase('connectionString');
const getSpriteById = async (spriteId) => {
// throws exception if it doesn't find the record
const sprite = await db.findById(spriteId);
return sprite;
};
export { getSpriteById };
(By the way the code is pseudocode, don't expect it to work if you actually run it. However, it showcases the point.)
In the example, the function getSpriteById searches the database. If it doesn't find the record it's looking for, it throws an exception. It doesn't handle the error itself. Instead, the handlers in server.js decide how to handle the error. Both handlers have try / catch blocks which handle the exception differently based on what they need.
(For exceptions) Be careful of how much code you put in your try blocks
It's considered best practice to put as little code as possible in each try / catch block. This means that you may need multiple try / catch blocks, instead of just one.
The benefits of this are that:
- it's easy to see which code raises which exceptions (and which code doesn't raise exceptions)
- it "separates concerns" more clearly. Each try / catch block is a separate piece of functionality. This makes it easier to refactor it into a separate function.
- it prevents the accidental swallowing of exceptions. This happens if you put some code in
trywithout thinking. That code might throw an exception that you weren't prepared to handle. However, it will be caught incatch(and potentially handled incorrectly). Then, the program will continue executing, potentially producing the wrong result.
It's also a solution for when certain lines of code can throw the same type of exception, but each case needs to be handled differently.
On the flip side, having small try / catch blocks can make the code more verbose.
In the end, you need to be pragmatic. Keep the benefits and downsides in mind. Then, make your decision. Usually, correctness and clarity are more important, even if they're more verbose. However, it's okay to make the code more concise sometimes, especially if you don't think correctness and clarity are too affected.
For example, this code could be separated further, but is still pretty good:
BufferedReader bufferedReader = null;
try {
bufferedReader = new BufferedReader(new FileReader("path"));
String line = bufferedReader.readLine();
while (line != null) {
doSomething(line);
line = bufferedReader.readLine();
}
} catch (FileNotFoundException | IOException e) {
e.printStackTrace();
} finally {
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
Here is the same example separated more:
BufferedReader bufferedReader = null;
try {
bufferedReader = new BufferedReader(new FileReader("path"));
try {
String line = bufferedReader.readLine();
while (line != null) {
// we’re leaving this line here for simplicity, but depending
// on how it works, it might need its own try block
doSomething(line);
line = bufferedReader.readLine();
}
} catch (IOException e) {
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
The second version would be necessary if each catch block needed to have different code. Otherwise, you can choose either version.
(The best solution is probably to use a with / using / try-with-resources statement, or the equivalent for your programming language. It automatically closes the bufferedReader at the end. The code above is just to showcase the point.)

Restore state and resources
If you successfully handle an error, then the program should be able to continue executing correctly. It should continue almost as though the error never happened.
This means that you need to:
- restore state to something correct
- close any side effects that were started by erroring code
Restore state
After recovering from an error, your program needs to have the correct state. If it doesn't, then you haven't really recovered.
This means that you might need to fix or restore your program's state in your error handling code.
Here's an example.
Consider that you have a Boolean variable. The Boolean variable should start as false. However, while some code is running, you set it to true. At the end, you set it to false again.
But, if the program errors at some point, the variable won't be reset. This will leave your program in a bad state, even if the error is handled.
Here's an example of some "dangerous code", which will have invalid state if an error occurs:
let isBusy = false;
async function handleUserEvent(event) {
if (!isBusy) {
isBusy = true;
// do something asynchronous which may throw an exception, for example:
// await doSomething()
isBusy = false;
}
}
If handleUserEvent errors, the value of isBusy will remain false forever. handleUserEvent won't be able to run properly again.
For that reason, you need to manually reset the state if an error occurs.
Here's a code example:
let isBusy = false;
async function handleUserEvent(event) {
if (!isBusy) {
isBusy = true;
try {
// do something asynchronous which may throw an exception, for example:
// await doSomething()
} finally {
isBusy = false; // fix the state
// exception is sent higher up because there's no catch block
}
}
}
// equivalent example
async function handleUserEvent(event) {
if (!isBusy) {
isBusy = true;
try {
// do something asynchronous which may throw an exception, for example:
// await doSomething()
} catch (error) {
isBusy = false; // fix the state
throw error;
}
isBusy = false;
}
}
In this example, if an error occurs in handleUserEvent, there's no problem. The state is restored and handleUserEvent will execute correctly afterwards.
The same principle applies across all of your code in the call stack. Imagine that an error occurs in function bar. But, you handle the error in function foo, which is 5 function calls earlier in the call stack. For the program to be in a valid state, you need to make sure that you've fixed all of the state from bar to foo.
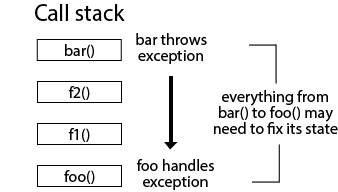
Basically, it means that you may need many intermediate try / catch blocks in different functions in the call stack. You fix the state in each one. That way, if the error is handled higher up, the state of all the intermediate code has been fixed. They can run again as though nothing went wrong.
For example:
// handleUserEvent
import foo from './foo.js';
// this is the top-level function
async function handleUserEvent() {
try {
await foo();
} catch (error) { // handle the error at the top level
// record error
// display message to user that action didn't work
}
}
// foo.js
import bar from './bar.js';
let isBusy = false;
async function foo() {
if (isBusy) {
return;
}
isBusy = true;
try {
await bar();
} finally {
isBusy = false; // restore this module's state
// exception is sent further up because there is no catch block
}
}
export default foo;
// bar.js
let isBusy = false;
async function bar() {
if (isBusy) {
return;
}
try {
// do something asynchronous which may throw an exception, for example:
// await doSomething()
} finally {
isBusy = false; // restore this module's state
// exception is sent further up because there is no catch block
}
}
export default bar;
(Yes, I know the code in the examples is very contrived, but hopefully it illustrates the point 😅)
Close side effects
Some side effects come in pairs. For example, if you open a file, you should also close it. It can be unsafe to leave it open.
So, make sure that resources like that are properly released.
If you use exceptions:
- use
withblocks. These automatically close resources if an error occurs. Some examples arewithin Python,try-with-resourcesin Java orusingin C#. - otherwise, use
finallyblocks (or their equivalent in different programming languages)
If you're using error values, place the "closing" code somewhere appropriate. It should run both in the error case and the non-error case.
Here's an example with finally:
// pseudocode
let file;
try {
file = openFile('foo.txt'); // open the resource
writeToFile(file, 'bar');
} catch (error) {
// code to handle exceptions
} finally {
close(file); // close the resource
}
Here's an example with error values:
// pseudocode
const [fileError, file] = openFile('foo.txt');
if (fileError) {
// handle error
close(file);
return;
}
const [writeError, _] = writeToFile(file.value, 'bar');
if (writeError) {
// handle error
}
close(file);
Final notes
So that's it for this article. I hope that you found it useful.
As always, if any points were missed, or if you disagree with anything, or have any comments or feedback then please leave a comment below.
For the next steps, I recommend looking at the other articles in the error handling series.
Alright, thanks and see you next time.
Credits
Image credits:
- Net - Photo by Raghavendra Saralaya on Unsplash
- Arrow - Photo by Hello I'm Nik on Unsplash
- Squirrel in treehouse - Photo by Joakim Honkasalo on Unsplash



